See below for an explanation of options on all three tabs of the k-Means Clustering dialog: Data, Parameters and Scoring tabs.
The following options appear on all three tabs of the k-Means Clustering dialog.

Help: Click the Help button to access documentation on all k-Means Clustering options.
Cancel: Click the Cancel button to close the dialog without running k-Means Clustering.
Next: Click the Next button to advance to the next tab.
Finish: Click Finish to accept all option settings on all three dialogs, and run k-Means Clustering.
k-Means Clustering Data Tab
See below for documentation for all options appearing on the k-Means Clustering Data tab.
k-Means Clustering Data tab
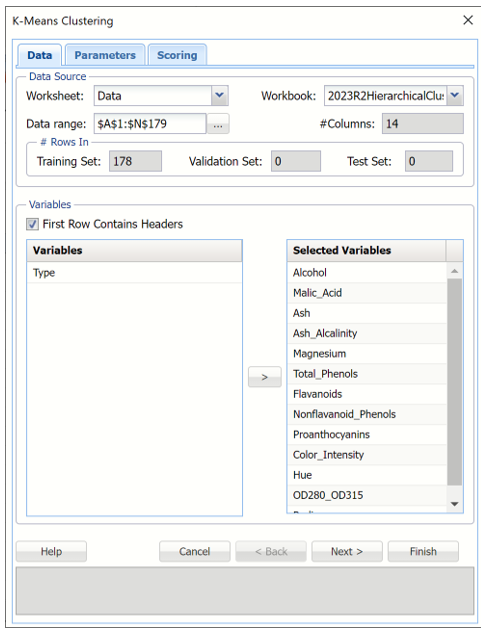
Data Source
Worksheet: Click the down arrow to select the desired worksheet where the dataset is contained.
Workbook: Click the down arrow to select the desired workbook where the dataset is contained.
Data range: Select or enter the desired data range within the dataset. This data range may either be a portion of the dataset or the complete dataset.
#Columns: Displays the number of columns in the data range. This option is read only.
#Rows In Training Set, Validation Set and Test Set: Displays the number of columns in training, validation and/or test partitions, if they exist. This option is read only.
Variables
First Row Contains Headers: Select this checkbox if the first row in the dataset contains column headings.
Variables: This field contains the list of the variables, or features, included in the data range.
Selected Variables: This field contains the list of variables, or features, to be included in k-Means Clustering.
- To include a variable in k-Means Clustering, select the variable in the Variables list, then click > to move the variable to the Selected Variables list.
- To remove a variable as a selected variable, click the variable in the Selected Variables list, then click < to move the variable back to the Variables list.
k-Means Clustering Parameters Tab
See below for documentation for all options appearing on the k-Means Clustering Parameters tab.
k-Means Clustering Parameters tab
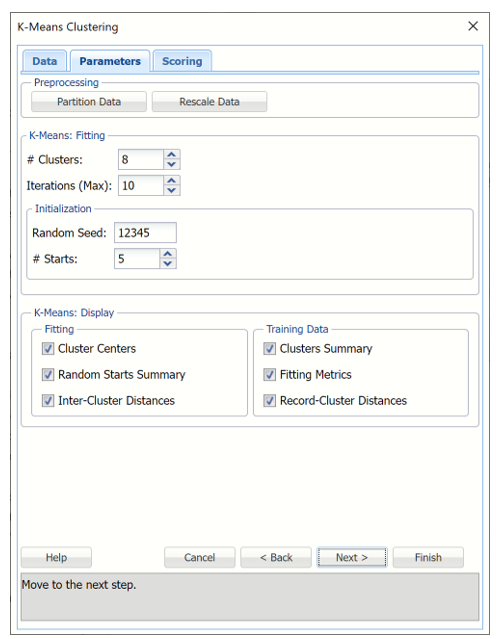
Preprocessing
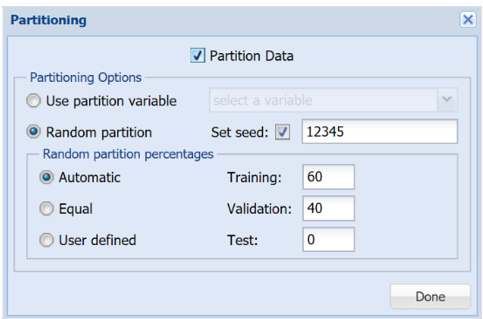
Analytic Solver Data Science allows partitioning to be performed on the Parameters tab for k – Means Clustering, if the active data set is un-partitioned. If the active data set has already been partitioned, this button will be disabled. Clicking the Partition Data button opens the following dialog. Select Partition Data on the dialog to enable the partitioning options. See the Partitioning chapter for descriptions of each Partitioning option shown in the dialog below.
Partitioning "On-the-fly" dialog
Rescale Data
Use Rescaling to normalize one or more features in your data during the data preprocessing stage. Analytic Solver Data Science provides the following methods for feature scaling: Standardization, Normalization, Adjusted Normalization and Unit Norm. If the input data is normalized, k-Means Clustering operates on rescaled data. Results are not transformed back to their original scale.
For more information on this feature, see the Rescale Continuous Data section within the Transform Continuous Data chapter that occurs earlier in this guide.
Why use “on-the-fly” Partitioning and Rescaling?
If a data partition will be used to train and validate several different algorithms that will be compared for predictive power, it may be better to use the Ribbon Partition choices to create, rescale and/or partition the dataset. But if the rescaled data and/or data partition will be used with a single algorithm, or if it isn’t crucial to compare algorithms on exactly the same data, “Partition-on-the-Fly” and “Rescale-on-the-fly” offers several advantages:
- User interface steps are saved, and the Analytic Solver task pane is not cluttered with partition and rescaling output.
- Partition-on-the-fly and Rescaling-on-the-fly is much faster than first rescaling the data, creating a standard partition and then running an algorithm.
- Partition-on-the-fly and Rescaling-on-the-fly can handle larger datasets without exhausting memory, since the intermediate partition results for the partitioned data is never created.
# Clusters
Enter the number of final cohesive groups of observations (k) to be formed here. The number of clusters should be at least 1 and at most the number of observations-1 in the data range. This value should be based on your knowledge of the data and the number of projected clusters. One can use the results of Hierarchical Clustering or several values of k to understand the best value for # Clusters. The default value for this option is 2.
# Iterations
This option limits the number of iterations for the k-Means Clustering algorithm. Even if the convergence criteria has not yet been met, the cluster adjustment will stop once the limit on # Iterations has been reached. The default value for this option is 10.
Random Seed
This option initializes the random number generator that is used to assign the initial cluster centroids. Setting the random number seed to a nonzero value (any number of your choice is OK) ensures that the same sequence of random numbers is used each time the initial cluster centroids are calculated. The default value is “12345”. The minimum value for this option is 1. To set the seed, type the number you want into the box. This option accepts positive integers with up to 9 digits.
# Starts
Enter a positive value greater than 1 for this option, to enter the number of desired starting points. The final result of the k-Means Clustering algorithm depends on the initial choice on the cluster centroids. The “random starts” option allows a better choice by trying several random assignments. The best assignment (based on Sum of Squared Distances) is chosen as an initialization for further k-Means iterations.
k-Means Display
Use these options to display various output for k-Means Clustering. Output options under Fitting apply to the fitting of the model. Output options under Training are related to the application of the fitted model to the training partition.
Fitting: Output appears on the KMC_Output worksheet
- Cluster Centers
- The Cluster Centers table displays detailed information about the clusters formed by the k-Means Clustering algorithm. This table contains the coordinates of the cluster centers found by the algorithm.
- Accessible by clicking the Clusters Centers link on the Output Navigator.
Example of Cluster Centers output

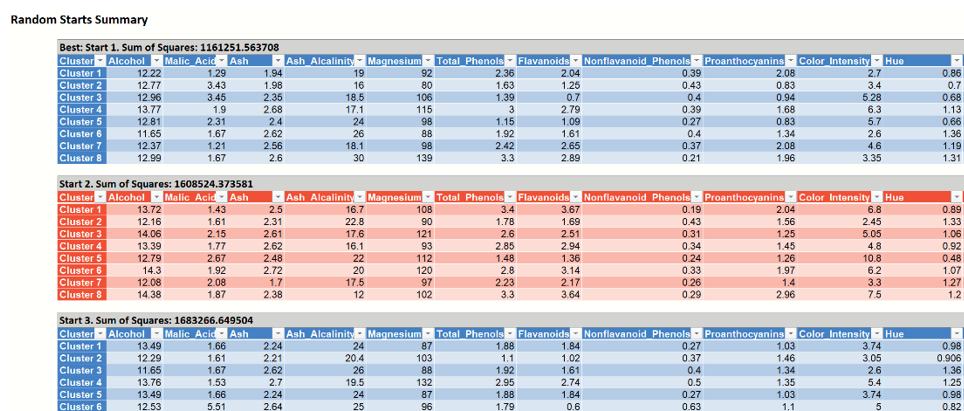
- Random Starts Summary
- The table “Random Starts Summary” displays the information about the initial search for the best centroid assignment. The assignment marked by “Best Start” is used as the initial assignment of the centroids. Accessible by clicking the Random Starts Summary link on the Output Navigator.
Example of Random Starts Summary output
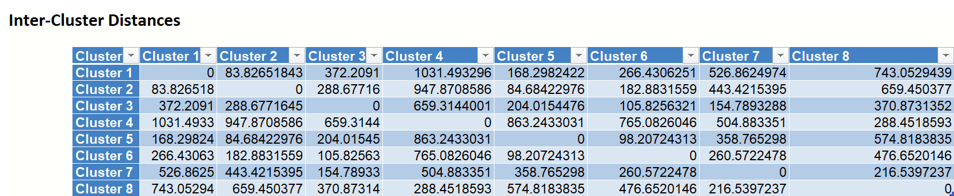
- Inter-Cluster Distances
- This table displays the distance between each cluster center. Accessible by clicking the Inter-Cluster Distances link on the Output Navigator.
Example of Inter-Cluster Distances output
Training Data Output appears on the KMC_TrainingClusters worksheet
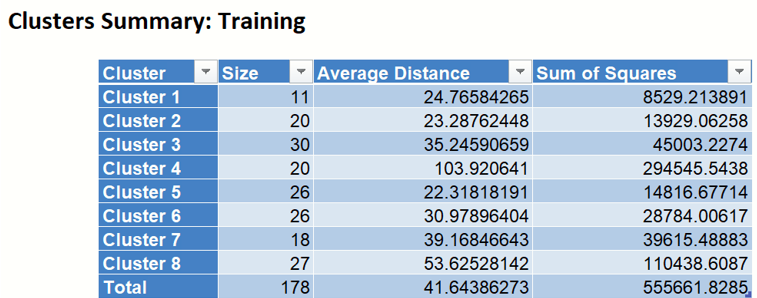
- Clusters Summary
- The "Cluster Summary" table displays the number of records (observations) included in each cluster, the within-cluster average distance and the total Sum of Squares. This information can be used to better understand how large and how sparse the resulting clusters are. Accessible by clicking the Clusters Summary link on the Output Navigator.
Example of Clusters Summary output
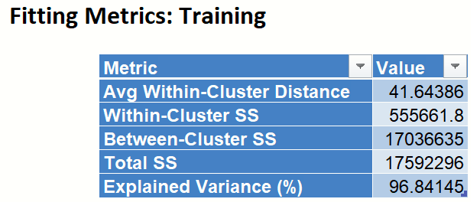
- Fitting Metrics
- Fitting Metrics: This table lists several metrics computed from the training dataset and is accessible by clicking the Fitting Metrics: Training link on the Output Navigator.
- (Recall that our training dataset is the full dataset since we did not partition into training, validation or test partitions.)
- Avg Within-Cluster Distance – Average total distance from each record to the corresponding cluster center, for each cluster.
- Within Cluster SS – Sum of distances between the records and the corresponding cluster centers for each cluster. This statistic measures cluster compactness. (The algorithm is trying to minimize this measure.)
- Between Cluster SS – Sum of distances between the cluster centers and the total sample mean, divided by the number of records within each cluster. (Between Cluster SS measures cluster separation which the algorithm is trying to maximize. This is equivalent to minimizing Within Cluster SS.)
- Total SS – Sum of distances from each record to the total sample mean, Total SS = Within Cluster SS + Between Cluster SS.
- Explained Variance (%) – Goodness of fit metrics, showing the degree of internal cohesion and external separation, Explained Variance % = Between Cluster SS / Total SS.
- Clusters: Training - This table displays the final cluster assignment for each observation in the input data – the point is assigned to the "closest" cluster, i.e. the one with the nearest centroid.
Example of Fitting Metrics output
- Record-Cluster Distances
- Appends the distance of each record to each cluster in the Clusters: Training output table. Records are assigned to the "closest" cluster, i.e. the one with the nearest centroid. For example, in the 4th record, the final cluster assignment is 4 since the distance to that cluster centroid is the closest (119.34).
Example of Record-Cluster Distances output

k-Means Clustering Scoring Tab
See below for documentation for all options appearing on the k-Means Clustering Scoring tab.
k-Means Clustering Scoring Tab
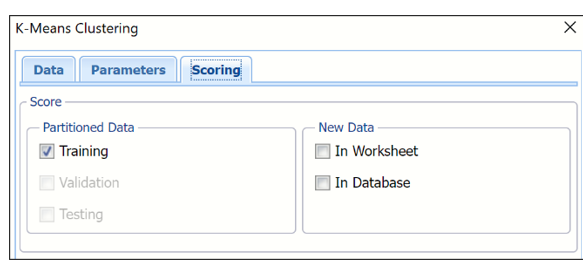
Scoring Tab
Select the desired partition to apply k-Means Clustering, if the partition exists. If Validation and/or Testing partitions do not exist, then these two options will be disabled.
See k-Means Clustering example or Scoring for information on how to score new data In Worksheet or In Database.